This work was for CMU’s 10-701 Introduction to Machine Learning course. The project revolved around classification of shoeprints. The problem was broken up into two parts: 1) learn to classify degraded images of shoeprints as either left foot or right foot shoes and 2) using a single clean photo from 1,000 different shoeprints, classify noisy versions of these prints into their original class.
This project was held as a Kaggle-style competition with a community leaderboard comparing results. My work here produced a top-5 result in a course of 200 students.
Left/Right Shoeprint Classification
The first task was: given a collection of shoeprints labeled as right or left shoes, correctly classify unseen prints. We were given 10,000 training images with another 10,000 validation images to experiment with before making predictions on test data that we had no labels for. The prints that we were given came in a range of quality, from nearly vertical full prints that could be easily identified as one foot or another, to rotated and cropped images with lots of noise making it hard for even human eyes to discern the correct label.

I implemented a convolutional neural network with a VGG-16 like architecture in Keras using a Tensorflow backend. I chose VGG-16 because of its proven performance in ImageNet competitions, and its size relative to other state-of-the-art models (training was done on CPU only).
Before being passed through the network, images were pre-processed to improve training. By using a Sobel filter I was able to isolate the edges of the rotated images and using RANSAC obtained lines corresponding to the angle of rotation. Once the images were rotated so the shoeprints sat vertically, they were resized to have the same dimensions. Then, by applying a series of filters, I reduced the image noise while leaving as much of the print as possible.
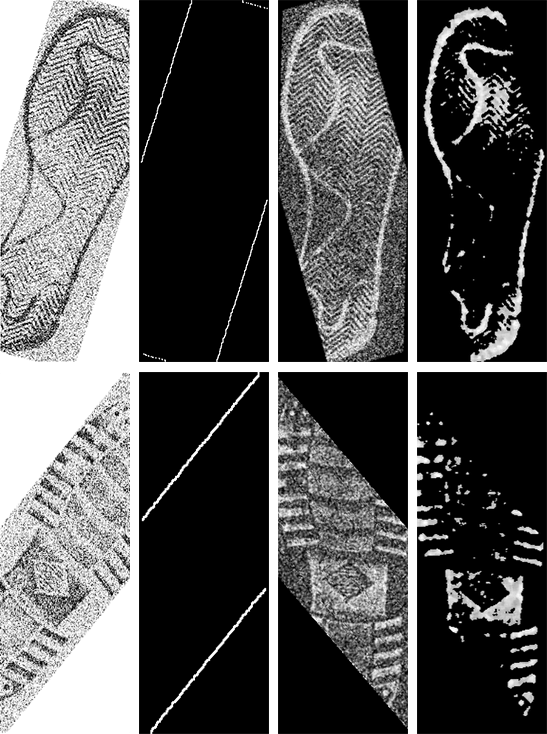
I trained the network from scratch, adjusting the learning rate when the validation error stopped decreasing. I also added randomly shifted images, vertically and horizontally, to increase the dataset size and improve network robustness.
After training I was able to achieve 96.5% accuracy on the validation dataset, and 95.8% accuracy on the test set.
Shoeprint Matching
The second task was: given a database of 1,000 “clean” shoeprints, classify noisy prints into one of the 1,000 possible classes. Again we were given 10,000 training and validation images to work with.
To approach this problem I looked through the validation images that we were to classify and found these images had noise, scale, and rotation properties that were similar to the ones from the first problem. I created a generator that would produce images similar to the validation images, in the hopes of training on data that was nearly identical to what we would be testing on. For each image I created 35 modified versions (35,000 images total) that had scaling, cropping, exposure, rotation, blurring, and Gaussian noise applied following some Gaussian distribution for each operation. I manually tuned the mean and variance properties of the operations to make the generated images visually indistinguishable from training and validation images.

Using this new dataset I trained the CNN from the first section with 1,000 possible classes. At the time of submission this network had a classification accuracy of 99.5% on the validation set and 98.3% on the test set.
